Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。
它是一个专注于实时处理的任务队列,同时也支持任务调度。
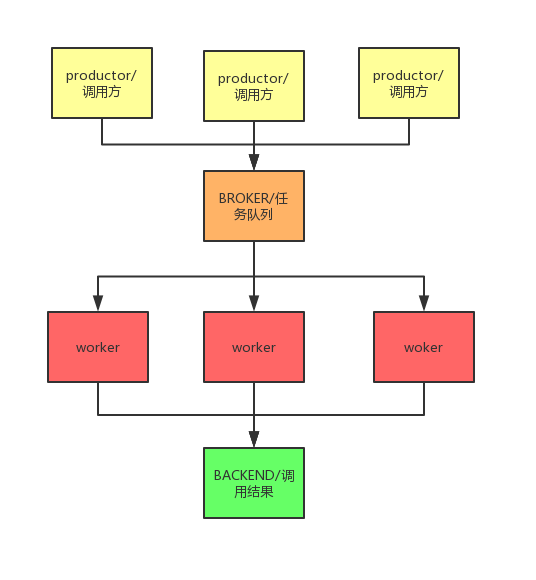
原理
在celery 中主要有4个角色,productor ,broker,worker,backend
productor 作为生产者发布任务
broker 是消息队列 用于存储任务 官方推荐使用 RabbitMQ 或者redis
worker 消费者, 任务处理逻辑
backend 处理结果
如何使用
配置
1 | #!/usr/bin/env python |
worker
1 | #!/usr/bin/env python |
进入work 所在的目录 执行命令 celery -A task worker –loglevel=INFO -n worker1.%h
worker 就启动起来了(可以启动多个, 注意修改一下名字作区分)
调度任务(product)
1 | #!/usr/bin/env python |